Reconnaissance de mots-clés dans un discours
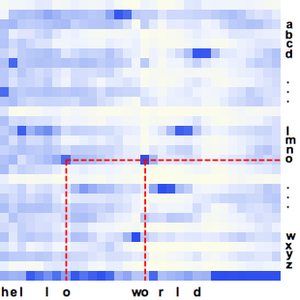
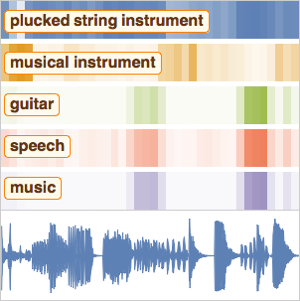
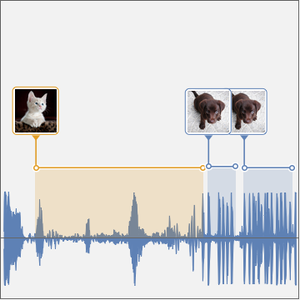
En plus d'une simple transcription de discours, calculer la probabilité qu'un enregistrement contienne l'un ou l'autre d'un ensemble restreint de mots peut permettre de résister aux erreurs d'orthographe que le réseau pourrait commettre. De plus, il peut être très utile de localiser l'endroit où un mot spécifique est prononcé dans un enregistrement.
Utilisez le réseau de reconnaissance vocale pré-entraîné de Wolfram Neural Net Repository pour calculer la probabilité qu'un changement de code contienne un mot spécifique. Voir les détails de ce réseau ici.
Commencez par télécharger et examiner un échantillon des données d'entraînement de "Spoken Digit Commands" dans Wolfram Data Repository.
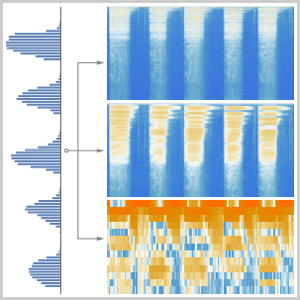
Calculez les probabilités de n'importe quelle lettre à tout moment en utilisant le réseau.
Vous pouvez utiliser CTCLossLayer pour calculer la probabilité logarithmique négative d'une séquence spécifique de caractères en fonction de la sortie du réseau.
Calculez les probabilités logarithmiques de la transcription correspondant à l'un des chiffres se situant entre 0 et 9.
Vous pouvez faire la même opération sur un échantillon audio plus long en utilisant une fenêtre coulissante.
Calculez les probabilités de n'importe quelle lettre à tout moment en utilisant le réseau.
Choisissez les candidats à la transcription.
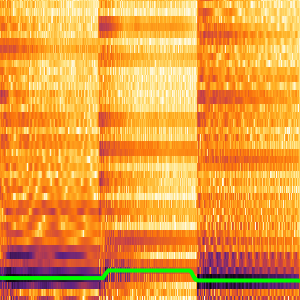
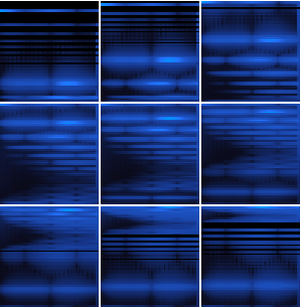
Vous pouvez partitionner les probabilités calculées par le réseau pour inspecter les sous-ensembles du signal. La perte de CTC peut être calculée par rapport à tous les choix pour chaque partition. Ceci produira la probabilité logarithmique d'un choix spécifique correspondant à la transcription de la partition spécifique. BlockMap est utilisé pour appliquer la fonction aux partitions du signal audio.
Vous pouvez maintenant tracer les probabilités des trois mots en fonction du temps.