用 FileSystemScan 创建莎士比亚文集
在此例中,我们将把莎士比亚的所有作品的文本文件放在一个目录中. 从利用 FileSystemMap 导入作品的文字内容开始,只收录文字内容.
显示完整的 Wolfram 语言输入
In[2]:=

works = Values[
FileSystemMap[Import, FileNameJoin[{$HomeDirectory, "Books"}], 2,
FileNameForms -> "*.txt"][[1]]]Out[2]=

用 StringJoin 构建一个文集.
In[3]:=
corpus = StringJoin[works]Out[3]=

现在可以把文集当作一个可以进行搜索的字符串,因而可以充分利用先进的文字处理程序. 使用 TextCases 来确定作品中提到了哪些国家,同时去掉重复并考虑大小写的情况.
In[4]:=
countries =
ToLowerCase[TextCases[corpus, "Country"]] // DeleteDuplicatesOut[4]=
显示完整的 Wolfram 语言输入
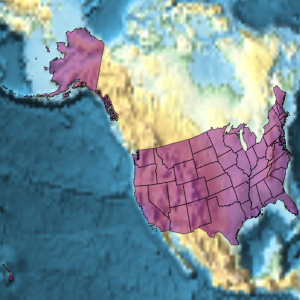
构建莎士比亚作品中提到的国家的 GeoListPlot.
In[6]:=
GeoListPlot[Interpreter["Country"] /@ countries]Out[6]=