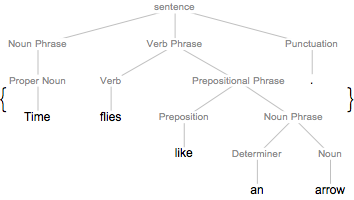
문장의 절 구조 비교
두 문장의 구조는 각각의 성분 그래프를 계산하고 처리하여 비교할 수 있습니다.
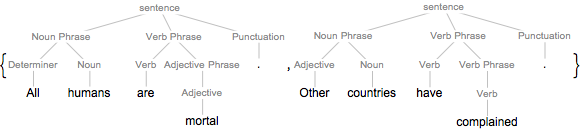
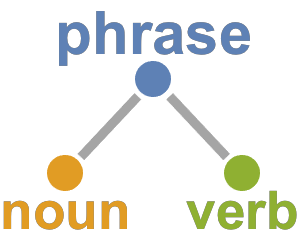
문장의 성분 트리를 그래프로 표시할 수 있습니다.
In[1]:=
graph = TextStructure["Time flies like an arrow.", "ConstituentGraph"]Out[1]=
그래프의 정점 사이의 거리를 취하는 것으로, 거리 행렬을 계산합니다.
In[2]:=
distancemat1 = GraphDistanceMatrix[First[graph]];
MatrixForm[distancemat1]Out[2]//MatrixForm=

다른 문장도 역시 위와 마찬가지로 실행합니다.
In[3]:=
graph2 = TextStructure["I fly in the sky.", "ConstituentGraph"];
distancemat2 = GraphDistanceMatrix[First[graph2]];그들의 거리 행렬을 비교하여 두 문장의 구조를 비교합니다.
In[4]:=
distancemat1 == distancemat2Out[4]=
이 두 문장은 동일한 구조를 가집니다.
다른 두개의 Wikipedia 아티클에서 동일한 구조의 문장을 찾습니다. 먼저 지정된 단어 수의 문장을 추출하여 각각의 성분 그래프를 생성합니다.
In[5]:=

processWikiPage[article_] :=
Select[TextCases[WikipediaData[article], "Sentences"],
WordCount[#] < 5 &];
genStructure[article_] :=
Flatten[TextStructure[#, "ConstituentGraph"] & /@
processWikiPage[article]];In[6]:=
phrasestruct1 = genStructure["Philosophy"];
phrasestruct2 = genStructure["History"];모든 거리 행렬을 계산합니다.
In[7]:=
adj1 = GraphDistanceMatrix /@ phrasestruct1;
adj2 = GraphDistanceMatrix /@ phrasestruct2;두개씩 다른 아티클의 문장을 비교합니다.
In[8]:=
comparison = Outer[Equal, adj1, adj2, 1];다음은 구조가 동일한 문장의 쌍입니다.
In[9]:=

pickedSentences =
Flatten[Pick[Outer[List, phrasestruct1, phrasestruct2], comparison,
True], 1];다음은 첫번째 쌍입니다.
In[10]:=
First[pickedSentences]Out[10]=