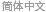문자 Vs. 첫 철자의 빈도
영어 사전에서 단어의 첫 철자로 가장 빈도가 높은 문자와, 가장 빈도가 높은 문자와 일치하지 않는 것을 나타냅니다.
자주 사용되는 영어 단어의 목록을 WordList에서 가져옵니다.
In[1]:=
Length[words = WordList[]]Out[1]=
각 단어의 첫 철자를 추출합니다.
In[2]:=
firstchars = StringTake[words, 1];각 문자로 시작하는 단어의 수를 계산합니다.
In[3]:=
Counts[firstchars]Out[3]=

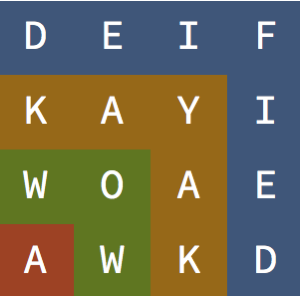
a WordCloud를 생성하여 각 문자의 상대적 빈도 우월성을 시각화합니다. 첫 철자로 가장 많이 사용되는 것은 자음 s, c, p, d입니다.
In[4]:=
WordCloud[firstchars]Out[4]=

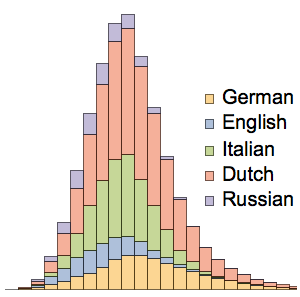
LetterCounts를 사용하여 모든 단어들의 모든 문자의 상대적 우위를 비교합니다.
In[5]:=
allchars = LetterCounts[StringJoin[words], IgnoreCase -> True]Out[5]=
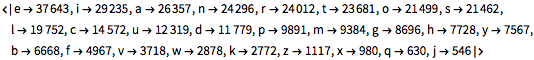
In[6]:=
WordCloud[allchars]Out[6]=