Ley de Zipf
La ley de Zipf afirma que en un conjunto de datos de una lengua, la frecuencia de una palabra es inversamente proporcional a su rango en la lista global de palabras luego de clasificarlas por su frecuencia de forma descendiente. Este ejemplo demuestra la ley con un conjunto de palabras en la novela de Miguel de Cervantes, Don Quixote, usando las nuevas funciones WordCount y WordCounts.
ExampleData contiene el texto en español del primer volumen de Don Quixote.
textSpanish = ExampleData[{"Text", "DonQuixoteISpanish"}];La muestra considerada aquí consiste en más de 180.000 palabras.
WordCount[textSpanish]Las cuentas de cada palabra distinta son dadas en una asociación por WordCounts. El resultado ya ha sido clasificado por cuentas decrecientes.
association = WordCounts[textSpanish];Take[association, 10]Tome las cuentas de las primeras 1.000 palabras más frecuentes.
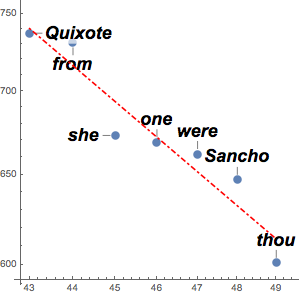
counts = Take[Values@association, 1000];Para aproximar dichas cuentas con una ley potente, tome logaritmos para usar un ajuste linear. La ley de Zipf afirma que el exponente debería ser aproximadamente 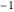 , y el resultado es un valor cerrado.
, y el resultado es un valor cerrado.
f[x_] = Fit[Log[Transpose[{Range[1000], counts}]], {1, x}, x]Visualice el ajuste junto con los datos actuales.


La ley de Zipf aplica en cualquier lengua así que el mismo cálculo puede ser realizado con la versión del inglés en Don Quixote.
textEnglish = ExampleData[{"Text", "DonQuixoteIEnglish"}];associationEnglish = WordCounts[textEnglish];
countsEnglish = Take[Values@associationEnglish, 1000];Take[associationEnglish, 10]De nuevo, el exponente encontrado es cercano a  .
.
Fit[Log[Transpose[{Range[1000], countsEnglish}]], {1, x}, x]