齐夫定律
齐夫定律(Zipf's law) 阐述了在语言的语料库中,一个单词出现的频率与其在频次递减排序中的排名成反比. 下面的例子用塞万提斯的小说《唐吉可德》中的词语集示范了该定律,其中使用了最新函数 WordCount 和 WordCounts.
ExampleData 包含了西班牙语《唐吉可德》上册中的文字.
In[1]:=
textSpanish = ExampleData[{"Text", "DonQuixoteISpanish"}];此处讨论的样本中包含了 180,000 多个单词.
In[2]:=
WordCount[textSpanish]Out[2]=
不同单词的个数由 WordCounts 以关联形式给出. 结果按频次递减排序.
In[3]:=
association = WordCounts[textSpanish];In[4]:=
Take[association, 10]Out[4]=
提取前 1,000 个频次最高的单词的计数.
In[5]:=
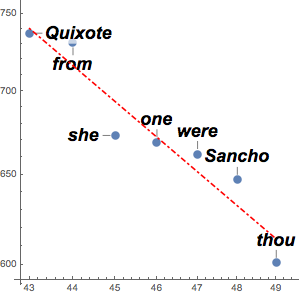
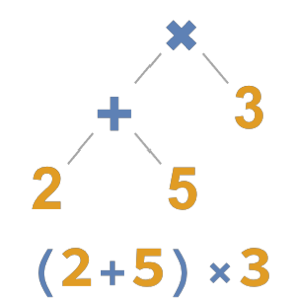
counts = Take[Values@association, 1000];为了能用幂次法则对这些计数进行近似,取对数以便进行线性拟合. 齐夫定律提示指数应近似为  ,结果与其极为相近.
,结果与其极为相近.
In[6]:=
f[x_] = Fit[Log[Transpose[{Range[1000], counts}]], {1, x}, x]Out[6]=
将实际数据和拟合一同可视化.
显示完整的 Wolfram 语言输入

Out[7]=

齐夫定律对任何语言都成立,因此可对英文版《唐吉可德》进行相同计算.
In[8]:=
textEnglish = ExampleData[{"Text", "DonQuixoteIEnglish"}];In[9]:=
associationEnglish = WordCounts[textEnglish];
countsEnglish = Take[Values@associationEnglish, 1000];In[10]:=
Take[associationEnglish, 10]Out[10]=
同样,所得指数非常接近  .
.
In[11]:=
Fit[Log[Transpose[{Range[1000], countsEnglish}]], {1, x}, x]Out[11]=