Use Transformer Neural Nets
Transformer neural nets are a recent class of neural networks for sequences, based on self-attention, that have been shown to be well adapted to text and are currently driving important progress in natural language processing. Here is the architecture as illustrated in the seminal paper Attention Is All You Need.
This example demonstrates transformer neural nets (GPT and BERT) and shows how they can be used to create a custom sentiment analysis model.
Load the GPT and BERT models from the Neural Net Repository.
These models are trained on large corpora of text (typically billions of words) on unsupervised learning tasks such as language modeling. As a result, they provide excellent feature extractors that can be used for various tasks. Given a sentence, these models output a list of numeric vectors, one for each word or subword; these vectors are a numeric representation of the "meaning" of each word/subword.
Now explore the inside of the BERT network. You can do this by clicking the part of the network you are interested in (and clicking again to dig deeper) or using NetExtract.
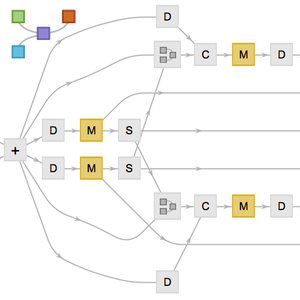
The input string is first tokenized into words or subwords. Each token is then embedded into numeric vectors of size 768.
The transformer architecture then processes the vectors using 12 structurally identical self-attention blocks stacked in a chain. The key part of these blocks is the attention module, constituted of 12 parallel self-attention transformations, a.k.a. "attention heads".
Extract one of these attention heads. Each head uses an AttentionLayer at its core. In a nutshell, each 768 vector computes its next value (a 768 vector again) by figuring out which vectors are relevant for itself. Note the use of the NetMapOperator here.
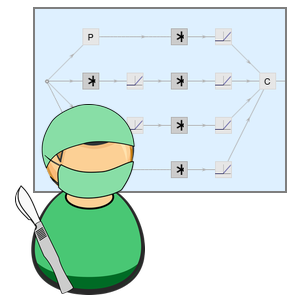
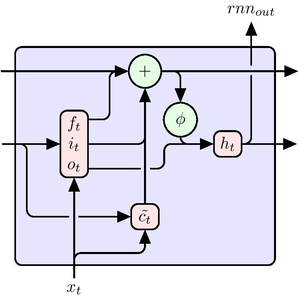
AttentionLayer can exploit long-term dependencies within sequences in a much more direct way than recurrent layers such as LongShortTermMemoryLayer and GatedRecurrentLayer. The following figure illustrates the connectivity of various sequence architectures.
GTP has a similar architecture as BERT. Its main difference is that it uses a causal self-attention, instead of a plain self-attention architecture. This can be seen by the use of the "Causal" mask in the AttentionLayer.
The causal attention is less efficient at text processing because a given token cannot obtain information about future tokens. On the other hand, causal attention is necessary for text generation: GPT is able to generate sentences, while BERT can only process them.
Several research articles report that transformers outperform recurrent nets for many language tasks. Check this on a classic movie sentiment analysis.
Here GPT and BERT are compared with baseline GloVe word embeddings and ELMo, which is the current state of the art for recurrent nets in NLP.
Some of the nets needs a bit of surgery so that they take a string as input and output a sequence of vectors.
Let's try several pooling strategies to make a sentence classifier out of the sequences of word embeddings.
Create a benchmarking function that trains and measures performance of a model based on a given embedding.
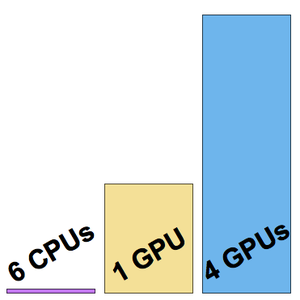
Run the benchmark (a GPU is advised) on all embeddings.
Visualize a benchmark report. As expected, contextual word embeddings based on the latest transformers outperform ELMo embeddings based on recurrent nets, which significantly outperform classical GloVe (context-independent) embeddings. Note that BERT is better than GPT (15% versus 18% error rate), since GPT is penalized by its causality constraint.