資料科學與產生報告
Wolfram 語言擁有處理資料和發表專業報告所需的一切。
從檔案輸入資料
使用資料科學需要數據,Wolfram 語言提供許多方法來輕鬆取得所需資料。内建的 Import 函數將輸入數百種常用的檔案格式。
1.使用預設值輸入資料。
Import 將自動輸入最常見的文件格式作為合適的表達式:

如果 Import 無法決定檔案格式,您可以明確指定:
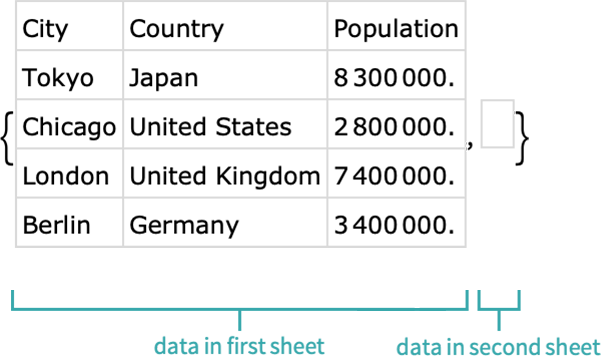
將資料輸入到 Dataset 物件也很容易,一個基於列表和關聯層次結構的結構化資料集,使遍歷大型資料集變得容易(和快速)。
2.將資料作為資料集輸入。
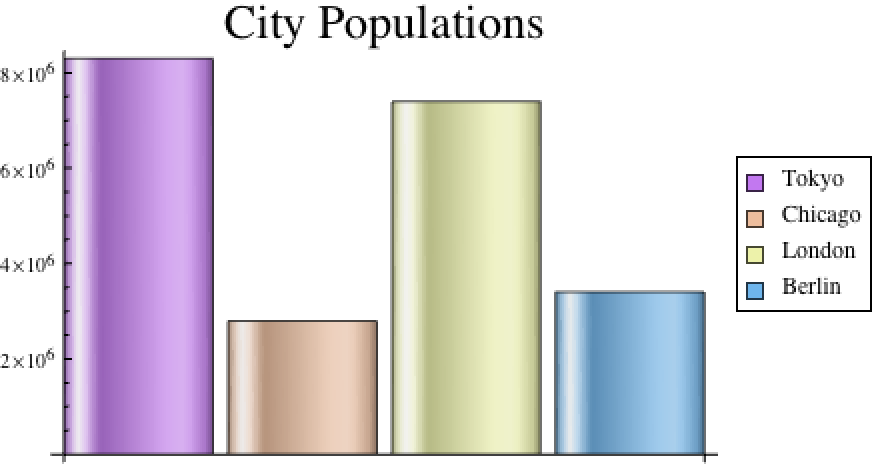
CSV、TSV、XLS 和 XLSX 等資料導向的格式將作為資料集輸入。將 "Dataset" 指定為第二個參數輸入。
Import 將自動把最常見的文件格式輸入為合適的表達式:

通常您想要可以從資料集中提取特定元素,而不必輸入整個資料集後再提取。使用一個附加參數,輸入函數可以直接提取特定元素。
3.從資料檔案或網頁輸入特定元素。
許多檔案和網頁包含 Import 設定返回資料以外的元素。透過將 "Elements" 作為 Import的第二個參數來獲取元素列表。
Import 將自動把最常見的文件格式輸入為合適的表達式:

指定要輸入的元素:
從 API 輸入資料
Wolfram 語言使得連接外部服務變得容易.本例通過 API 取得有關倫敦脚踏車車位共用的資料:

自動化分析
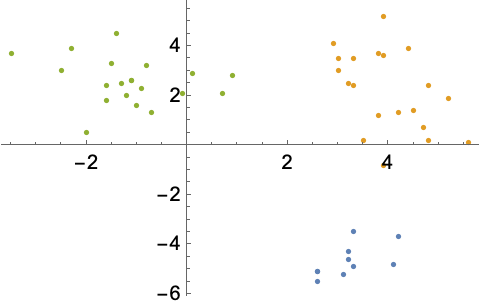
Wolfram 語言有數以千計的内建函數支援您的專案計劃,無需特定的技術細節。雖然您可以指派每個細節,但函數預設值的設計可以幾乎在所有情況下都發揮最佳效果,產生簡短易讀的代碼,即使是非常複雜的任務也是如此。本例中的二變量資料使用 FindClusters 函數自動叢聚。
在二變量資料中查找和視覺化叢聚:

FindDistribution 等高階函數可以分析資料,並使用各種統計方法找出超過三十五個分佈中最適合資料的分佈。
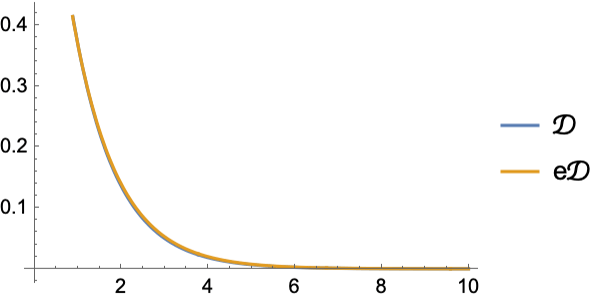
產生從指數分佈採樣的資料:
從資料中找到最佳分佈:
比較原始分佈和估計分佈的 PDF:
雲部署
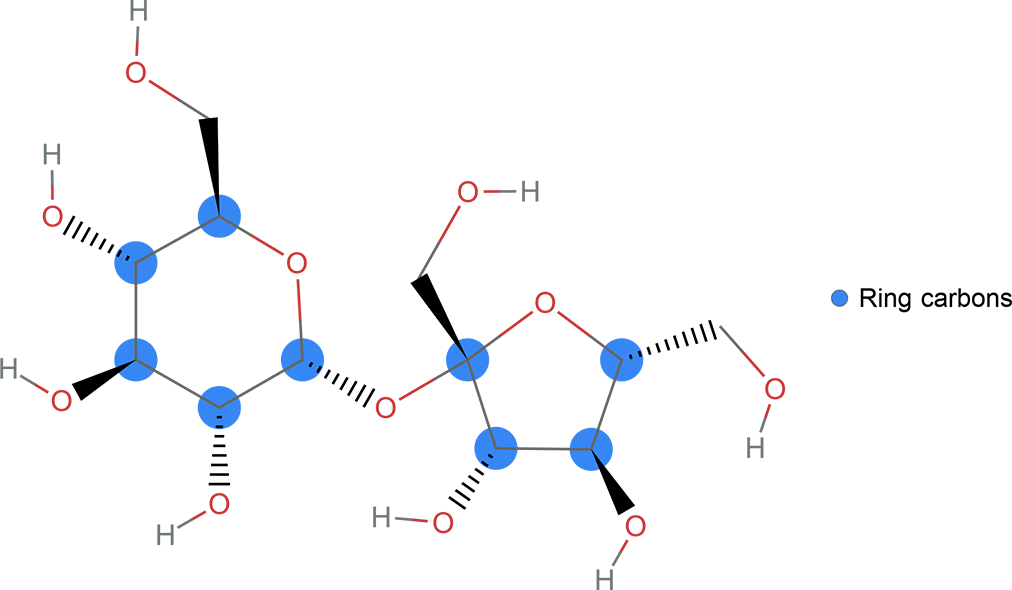
您通常會與他人共享程式,Wolfram 可以很容易將代碼變成獨立的互動式網頁。使用 CloudDeploy 函數可以將代碼公開到 Wolfram Research 伺服器並提供所有人或授予權限的人使用。本例為一個用於識別分子圖像的互動程式變成一個公共網頁。
1.製作要發布的內容:

學習資源
學習路徑
 先試後學
先試後學
想試試嗎?在專注嘗試於構建和部署網路應用程式的實際代碼範例的同時,感覺一下 Wolfram 語言的功能。
 免費取得 Wolfram 語言認證
免費取得 Wolfram 語言認證
課程設計讓您可以輕鬆學習 Wolfram 語言。試試免費互動課程並獲得認證。
進一步使用資料科學
如果想了解更多 Wolfram 提供的資料科學内容,請參閲 Wolfram 的資料科學和人工智慧方法。重要内容有:
- 可下載的範例
- 文件鏈接
- 講座、報告和演說
- 網路課程
- 技術資訊






